API Architecture Styles
- Anvita Bajpai
- Apr 27, 2023
- 4 min read

Updated: Apr 27, 2023

What is an API ?
An application programming interface (API) exposes the data of an application for use by other programs, called consumers. An API acts as an agreement between two systems to share data using a specific language and format. It is a set of rules that allow programs to talk to each other. The developer creates the API on the server and allows the client to talk to it.
Importance of choosing the right API Architecture strategy
The choice of API architecture is tightly coupled with your application’s non-functional requirements, which describe how you want it to behave and provide its main functionality.
Designing an effective API includes considering which design patterns to use, which architectural components to have, and how requests and responses flow between your consumers and data sources. A well-designed API architecture is easy to use and maintain, scalable, handles data and interactions securely, and is amenable to extension as new technologies and practices become available.
Tabular representation of some of the popular API Architecture Styles
Architecture Styles | Illustration | Use-Cases |
|---|---|---|
SOAP |  | XML-based for enterprise applications |
RESTful |  | Resource-based for web servers |
GraphQL |  | Query language reduce network load |
gRPC |  | High performance for microservices |
WebSocket |  | Bi-directional for low-latency data exchange |
Webhook |  | Asynchronous for event-driven application |
According to Postman's State of the API 2022 report, the most popular API architectural styles are: (* Note: This is a relative, not a cumulative percentage break down)
REST (89%)
Webhooks (35%)
SOAP (34%)
GraphQL (28%)
Websockets (26%)
gRPC (11%)
Brief Overviews of Some Popular API Architecture Styles
1. SOAP
Introduced by Microsoft and IBM around 1998, SOAP is an actual communication protocol. Known to use a bit wordy XML, SOAP is from the beginning a true API contract: its strict guidelines confer it an image of stability and safety. Today, SOAP is still found on some legacy systems which rely on it, but has mostly been supplanted by REST.
2. RESTful
REST stands for “Representational State Transfer”. It is a set of rules that developers follow when they create their API. One of these rules states that you should be able to get a piece of data (called a resource) when you link to a specific URL.
Each URL is called a request while the data sent back to you is called a response.


The six principles of REST
Client-server architecture
The principle behind the client-server architecture is the separation of problems. Dividing the user interface from data storage improves the portability of that interface across multiple platforms. It also has the advantage that different components can be developed independently from each other.
Statelessness
Statelessness means that the communication between client and server always contains all the information needed to execute the request. There is no session state on the server, it is kept entirely on the client. If access to a resource requires authentication, the client must authenticate itself on each request.
Caching
The client, server, and any intermediate components can cache all resources to improve performance. The information can be classified as cacheable or non-cacheable.
Uniform interface
All components of a RESTful API have to follow the same rules to communicate with each other. This also makes it easier to understand interactions between the various components of a system.
Layered system
Individual components cannot see beyond the immediate level they interact with. This means that a client that connects to an intermediate component such as a proxy does not know what is behind it. Therefore, components can be easily exchanged or expanded independently of each other.
Code-on-demand
Additional code can be downloaded to extend client functionality. However, this is optional because the client may not be able to download or execute this code.
3. GraphQL
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
GraphQL mantra is :
"Ask for what you need, get exactly that"
Send a GraphQL query to your API and get exactly what you need, nothing more and nothing less. GraphQL queries always return predictable results. Apps using GraphQL are fast and stable because they control the data they get, not the server.
4. gRPC
gRPC Remote Procedure Call (gRPC) is an open-source, contract-based, cross-platform communication protocol that simplifies and manages interservice communication by exposing a set of functions to external clients.
Built on top of HTTP/2, gRPC leverages features such as bidirectional streaming and built-in Transport Layer Security (TLS). gRPC enables more efficient communication through serialized binary payloads. It uses protocol buffers by default as its mechanism for structured data serialization, similar to REST’s use of JSON.
gRPC is widely used for communication between internal microservices majorly due to its high performance and its polyglot (compatible on several languages) nature.
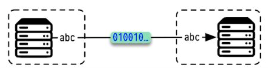
5. WebSocket
The WebSocket protocol, provides a way to exchange data between browser and server via a persistent connection. WebSocket allows us to create “real-time” applications which are faster and require less overhead than traditional API protocols. WebSocket is especially great for services that require continuous data exchange, e.g. online games, real-time trading systems and so on. Some example use-cases:
A real-time web application
Gaming Application
Creating a chat application
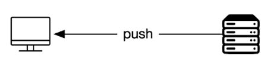
6. Webhook
A webhook is an HTTP-based callback function that allows lightweight, event-driven communication between two APIs.
Some advantages of Webhooks:
Eliminate the need for polling. This saves resources for the client application.
Are quick to set up. If an app supports webhooks, they are easy to set up through the server app’s user interface. This is where the client enters their app’s webhook URL and sets some basic parameters, like which event they are interested in.
Automate data transfer. The payload is sent as soon as the specified event happens on the server app. This exchange is initiated by the event, so it happens as quickly as the data can be transferred from server to client—as real-time as any data transfer can be.
Are good for lightweight, specific payloads. Webhooks rely on the server to determine the amount of data it sends, leaving it to the client to interpret the payload and use it in a productive way. Since the client does not control the exact timing or size of the data transfer, webhooks deal with small amounts of information between 2 endpoints, often in the form of a notification.


The material authenticity prioritized in the dutton ranch s01 outfits continues to inspire fashion enthusiasts tired of fast fashion's synthetic dominance. The costume department sourced genuine wool, heavyweight denim, oiled canvas, and full-grain leather that would actually withstand the demands of working ranch life. These natural fibers age beautifully, developing unique character through wear rather than degrading into unwearable condition after a single season. The commitment to quality materials sends a powerful message about investment dressing and conscious consumption. Fashion that honors craftsmanship and durability feels increasingly radical in a disposable culture.
Reading this article about API architecture styles, it really explains how different styles like REST, GraphQL, and WebSockets are used based on system needs and performance. It helped me understand how apps communicate and share data in structured ways . I remember a time when I was confused about APIs in a coding task, so I used computer assignment help to understand the flow better. It made things clearer and showed me that choosing the right approach always makes complex systems easier to manage.
Great breakdown of different API architecture styles. I especially appreciate how you explain RESTful, GraphQL, and Webhooks in a clear way. The article reminded me of how important structure is kind of like preserving traditional recipes to ensure consistency and success in software design.
North Western State Medical University is often discussed for its long academic history and structured medical curriculum. It’s interesting to see how traditional teaching methods are combined with modern medical education practices.